PEBBLE ACADEMY · Measurement
Why Measurement Is the First Step
Every serious carbon-reduction program starts the same way: a credible baseline. Without it, every "improvement" is a story without numbers, and finance, customers, and regulators are right to be skeptical.
For software workloads, the baseline question is "how much energy did this job actually use, and what does that mean in CO₂?" CodeCarbon answers exactly that, with a few lines of Python.
What CodeCarbon Does
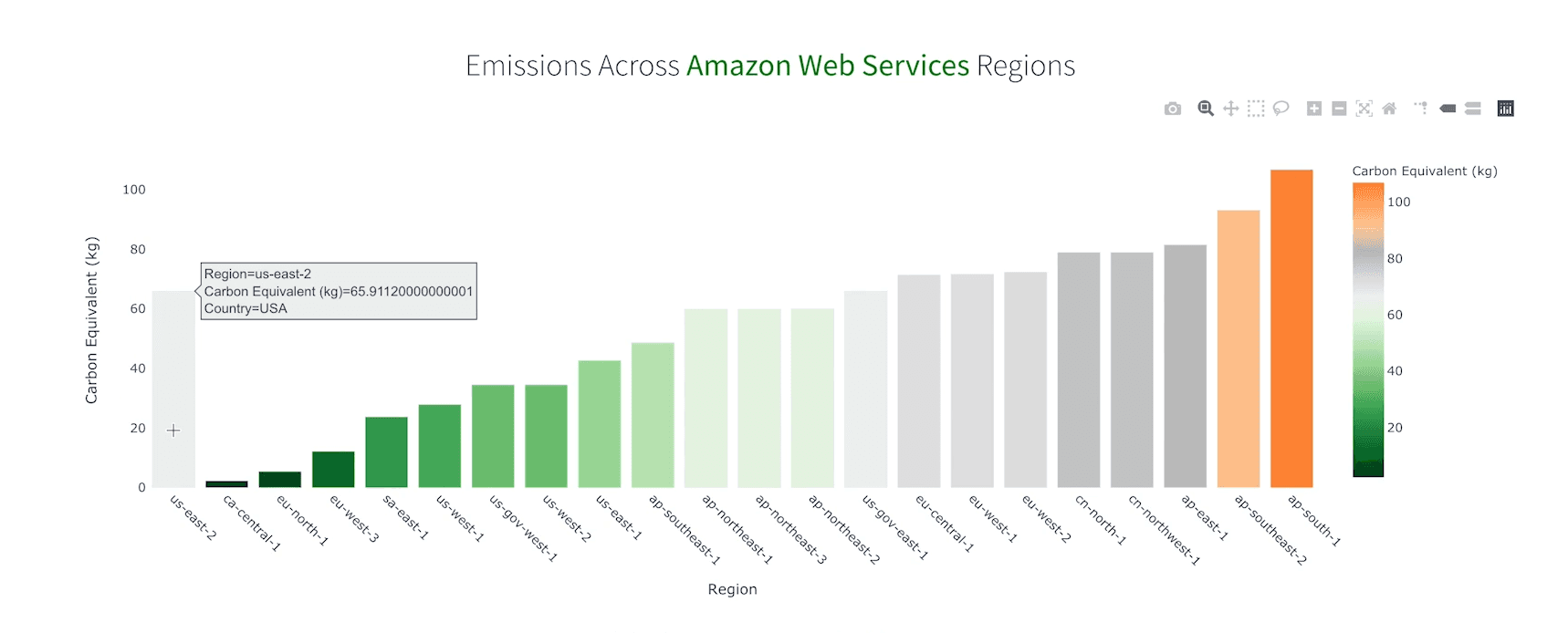
CodeCarbon is an open-source library that tracks the energy your code consumes — CPU, GPU, RAM — and converts that into estimated emissions based on the carbon intensity of the grid where you ran it. It works in notebooks, training scripts, and production pipelines.
Output goes to a CSV by default, but you can ship it to whatever observability stack you already use.
Adding It to a Training Run
from codecarbon import EmissionsTracker
tracker = EmissionsTracker(project_name="model-v3-finetune")
tracker.start()
# — your training loop —
emissions = tracker.stop()
print(f"Run emitted {emissions:.4f} kg CO2eq")That's it. Each run produces a row of energy consumed, region, hardware mix, and estimated CO₂ that you can roll up by experiment, by team, or by week.
From Tracking to Reduction
The numbers are useful on their own — engineers love seeing the impact of their code. But the bigger payoff is feeding them into a system that can act: scheduler decisions, region selection, model-size choices. Pebble integrates CodeCarbon-style telemetry directly so the same data that measures impact also drives optimization.